Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

Dans le monde de l’informatique, les bases de données relationnelles sont omniprésentes. Les applications que nous utilisons tous les jours, telles que les réseaux sociaux, les magasins en ligne et les services bancaires en ligne, utilisent des bases de données relationnelles pour stocker et gérer leurs données.
Dans cet article, nous explorons le monde passionnant des bases de données relationnelles. Nous passons en revue les concepts de base, tels que les modèles de données, les clés primaires et étrangères et le langage SQL, et nous discutons de la manière d’optimiser les performances des bases de données pour améliorer la vitesse d’accès aux données et la fiabilité des applications.
Une base de données relationnelle est un type de système de gestion de bases de données (SGBD) qui se base sur le modèle relationnel pour stocker et organiser les données. Ce type de base de données est le plus utilisé dans le monde de l’informatique, notamment pour la gestion des applications métier.
Le modèle relationnel est constitué d’entités et de relations entre ces entités. Les entités selon leur caractéristique telles que nom, taille, couleur, etc. et les relations selon les liens plus ou moins directs qu’ils ont entre eux. La base de données relationnelle permet de stocker les données de manière structurée en les organisant en tables, qui sont liées entre elles grâce aux clés primaires et aux clés étrangères.
Les SGBD relationnels les plus populaires sont : MySQL, Microsoft SQL Server, Oracle, PostgreSQL, et SQLite. Chacun de ces SGBD a des avantages et des inconvénients qu’il est important de comprendre afin de choisir la solution la plus adaptée à chaque contexte.
Pour qu’une base de données relationnelle soit efficace, il est crucial de bien la concevoir en respectant les principes du modèle relationnel. Ce dernier est basé sur les entités et les relations existantes entre ces entités.
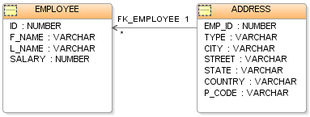
Les entités sont des objets ou des concepts pouvant être stockés dans la base de données. Par exemple, si nous gérons une bibliothèque, nous pourrions avoir plusieurs entités telles que « livre », « auteur » et « emprunteur ». Les relations entre ces entités sont des associations entre elles. Par exemple, un livre a un ou plusieurs auteurs, et chaque emprunt est associé à un livre et à un emprunteur.
Pour mettre en place ce modèle, il est essentiel de définir les clés primaires et les clés étrangères. La clé primaire est un identifiant unique permettant d’identifier chaque enregistrement dans la table. Dans notre exemple, l’ID d’un livre pourrait être la clé primaire de la table « livre ». La clé étrangère, quant à elle, permet de lier les entités en indiquant à quelle table elle fait référence. Par exemple, la clé étrangère « auteur_id » de la table « livre » serait liée à la clé primaire « id » de la table « auteur ».
Pour faciliter cette conception, des logiciels de modélisation de bases de données tels que MySQL Workbench ou PowerDesigner peuvent être utilisés.
SQL (Structured Query Language) est un langage de programmation couramment utilisé pour créer, manipuler et gérer des données dans une base de données relationnelle. Ce langage est considéré comme le standard pour les systèmes de gestion de bases de données relationnelles (SGBDR). Cette section vous présente les commandes les plus courantes du langage SQL pour créer et manipuler vos données.
Voici quelques exemples de requêtes SQL utilisant ces commandes :
SELECT * FROM ma_table;
INSERT INTO ma_table (nom, prenom, age) VALUES ('Dupont', 'Jean', 30);
UPDATE ma_table SET age = 31 WHERE nom = 'Dupont';
DELETE FROM ma_table WHERE nom = 'Dupont';
SQL propose également de nombreuses fonctions qui permettent d’effectuer des calculs sur les données. Voici quelques exemples :
Voici un exemple de requête SQL utilisant ces fonctions :
SELECT AVG(salaire), MAX(salaire), MIN(salaire), COUNT(*) FROM employes;
Cette requête calcule la moyenne, la valeur maximale, la valeur minimale et le nombre total de salaires dans une table d’employés.
L’optimisation des performances est essentielle pour assurer la bonne gestion d’une base de données relationnelle. En effet, avec l’augmentation de la taille de la base de données et du nombre de requêtes, les performances peuvent en pâtir. Pour cela, il est important de bien structurer la base de données, d’optimiser le traitement des données et de limiter la taille des résultats de recherche.
Pour optimiser la structure de la base de données, il est important de s’assurer que les tables sont correctement indexées, afin de faciliter les recherches et les jointures de table. Il est également recommandé d’adopter une structure de données dénormalisée pour éviter les jointures coûteuses. Enfin, il est important de veiller à une répartition équilibrée des données sur les différentes partitions ou disques.
Les requêtes SQL doivent être écrites avec soin pour éviter les comportements inefficaces. Il est important d’utiliser les index lorsque cela est possible et de limiter la taille des résultats de la requête en utilisant la clause LIMIT ou TOP. Il est également recommandé de diviser les requêtes en plusieurs requêtes plus petites plutôt que de combiner plusieurs requêtes en une seule requête complexe.



